What Do the Top 250 Vimrc's Have in Common?
As I was configuring Vim for the first time, I found myself browsing the various dotfile repositories on GitHub for inspiration. I was looking for a base configuration of sane settings that I could build upon. I kept trying to figure out what all of these popular .vimrc's had in common. Eventually, I thought, wouldn't it be easier to automate this?
🕵️♂️ Searching for Vimrc Files
To create a dataset of .vimrc lines, I used the GitHub API with PyGithub. I searched for repositories with "dotfiles" or "vimrc" in the name or description and sorted by the number of stars. For each repo, I looked for a file named .vimrc and pulled it out to include in the analysis. Instead of using a full database, I saved the data as a Python pickle file. Because I was executing these searches so rapidly, there were issues with rate limiting, and I had to include some timeouts in the code. I also made sure to save the data if there were any issues with the API requests so that I wouldn't have to start over from the beginning. It took a bit of work but eventually, I was able to get over 250 of the most-starred .vimrc files to analyze.
As a side note, I started off just searching by filename, which worked great. However, with over 230K results, it didn't seem feasible to get all of them through the GitHub API. This is why I ended up using a different search method and sorting by star-count. I figured if I'm only able to consider a small subset of the .vimrc's on GitHub, then it should at least be the most popular ones that make the cut.
🧼 Cleaning the Data
At this point, just searching for common lines wouldn't get great results. There were a lot of variations in the lines that weren't functionally significant. For example, differences in comments or whitespace, and multiple commands that do the same thing in Vim (called synonyms). These all needed to be standardized before counting the common lines.
First, I stripped out the whitespace from either end of each line. Next, I removed all lines that were comments (ie, started with ") or started with Vimscript keywords that I wasn't interested in (like else, endif, or return). Then I sorted them into categories for leader mappings, all other key mappings, plugins, and all other settings. The first three categories were based on keywords, and "all other settings" just contains the rest. Each category has its own formatting rules.
There was a lot of variation in how leader mappings were declared. For these, I just standardized the quotation marks and looked for the presence of ',', ' ', '\<Space>', etc. to figure out which mapping was being declared.
Other mappings had similar issues. I hardcoded a list of synonyms and made replacements to standardize the commands. The synonyms were mostly case-related so it was tempting to just convert everything to lowercase, but that wouldn't work. For example, <c-h> and<C-h> are the same, because capitalization of the control character doesn't matter, but <c-h> and <c-H> are different mappings. I then used spacing to break out the "from" and "to" of the mapping.
Plugins were a bit easier because the actual plugin name is almost always in quotes. So it was pretty straightforward to extract the plugin name from each line.
For the rest of the settings, I just made sure to remove any inline comments and strip any extraneous whitespace.
📝 Results
The actual analysis was simple. I just counted up the recurring lines. To present it more clearly, I sorted each line into a category: general settings, key mappings, and plugins. Key mappings include the keyword map, which covers common mapping commands like imap or nnoremap, and plugin lines started with Plug or similar. The general settings category includes everything else. I made bar charts showing how often each setting appeared and, to spice it up a bit, a few word clouds.
⚙️ General Settings
The most popular general settings are shown here:

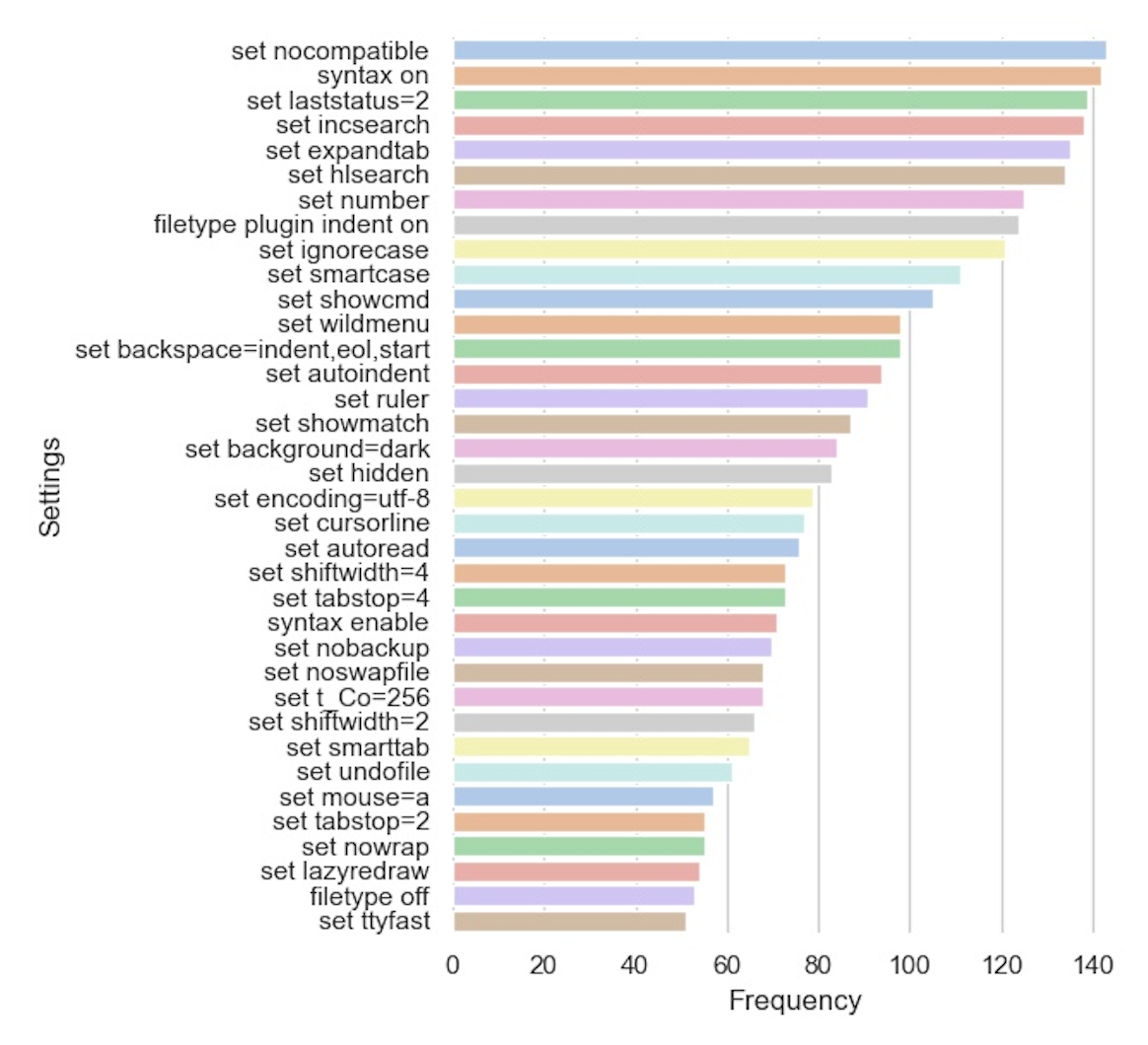
The most popular setting, set nocompatible, is required in some circumstances to enable the "improved" part of Vi Improved. Otherwise, we would be editing in a simpler mode that is compatible with the older Vi editor.
The next few settings in the list mostly contain UI improvements like enabling syntax highlighting, line numbering, and a status bar. They also improve the way searching works, convert typed tabs to spaces, and improve detection of code indentation.
It's also interesting to see set mouse=a on the list. That implies that a good amount of people at least get some use out of the mouse.
I personally like that set hidden made the list. This enables unsaved buffers to remain open in the background. I always found the default Vim behavior of forcing saves between buffer swaps to be really annoying and it took me a while before I found out I could modify that behavior.
Overall, I found this list really useful and will be researching some of these settings more to see if I want to incorporate them in my own .vimrc.
🗺 Key Mappings
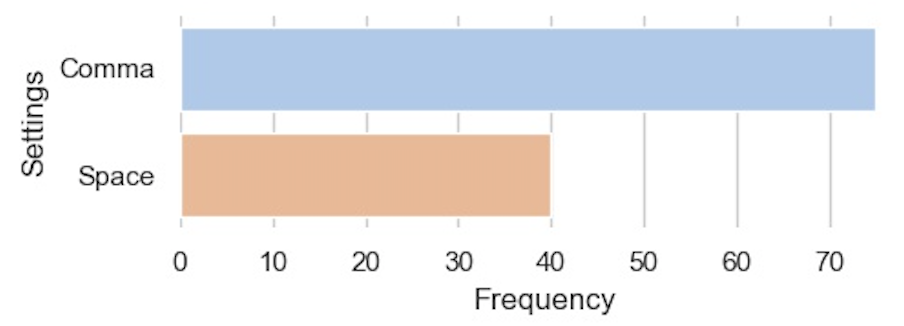
The leader key was remapped on almost half of the Vim configurations. Comma and space were by far the most common choices. Interestingly, comma was almost twice as frequent as space.
Other popular keyboard mappings are shown here:
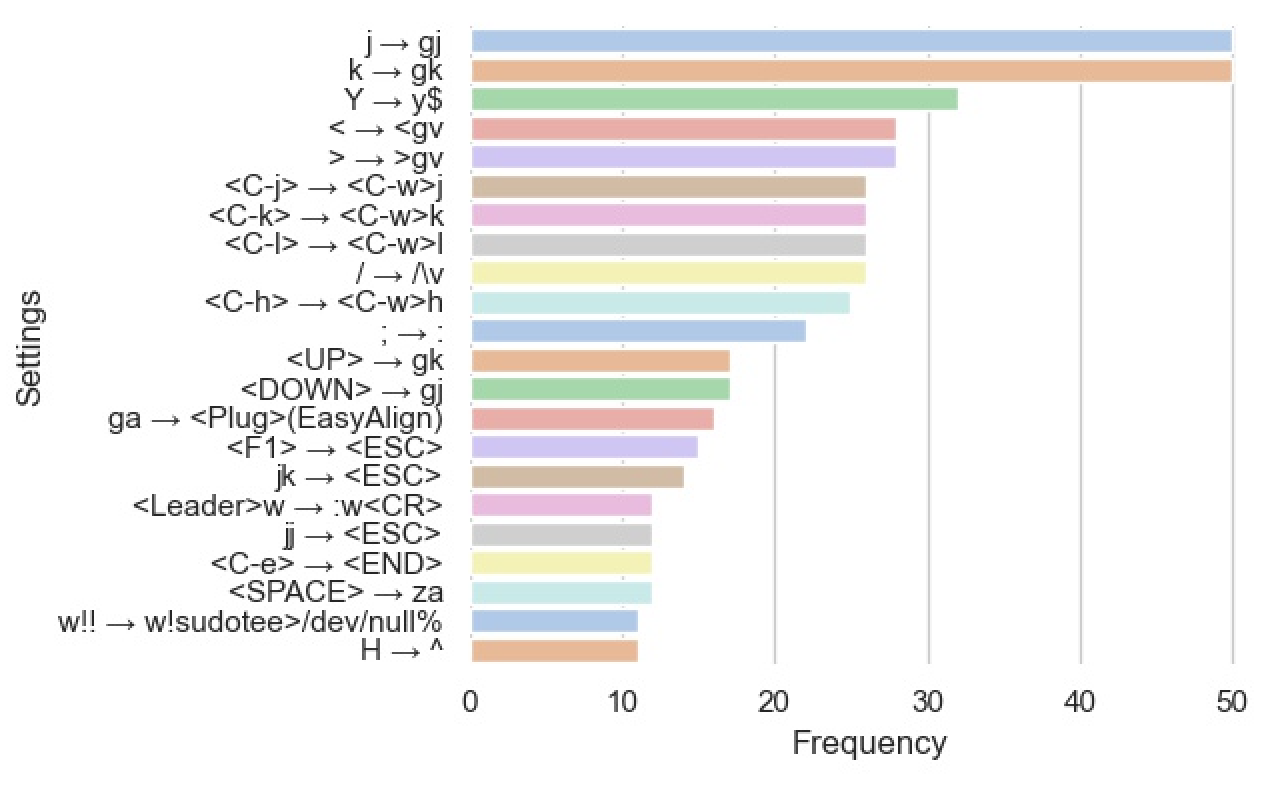
The most popular mappings, j to gj and k to gk, make it easier to navigate when your file has long lines. Typically in Vim, the j or k keys will only move up or down by one numbered line at a time. If that line is really long and wraps across multiple lines on the screen, you'll end up skipping over any of the wrapped parts of the line. This mapping changes that behavior to include those wrapped parts of the line.
The mapping of Y to y$ makes Y work in a way that is more consistent with the C and D family of commands.
It was also really common to see < and > remapped to <gv and >gv respectively. This just makes sure that if you hit the indent command in visual mode, you'll stay in visual mode with the same selection. The default behavior would be to exit visual mode.
There's a popular family of four mappings that makes it easier to navigate between split panes. Typically you'd have to hit <C-w> followed by the h, j, k, l key that corresponds to the direction you want to move. A lot of people just remap these movements to <C-h>, <C-j>, <C-k>, <C-l> so you can move between panes more easily.
There are several popular mappings for the <esc> key. Any time you're finished inserting text you need to hit <esc>, so it makes sense that many people would want to remap this to an easier-to-reach key.
🔌 Plugins
The most popular plugins are shown here:

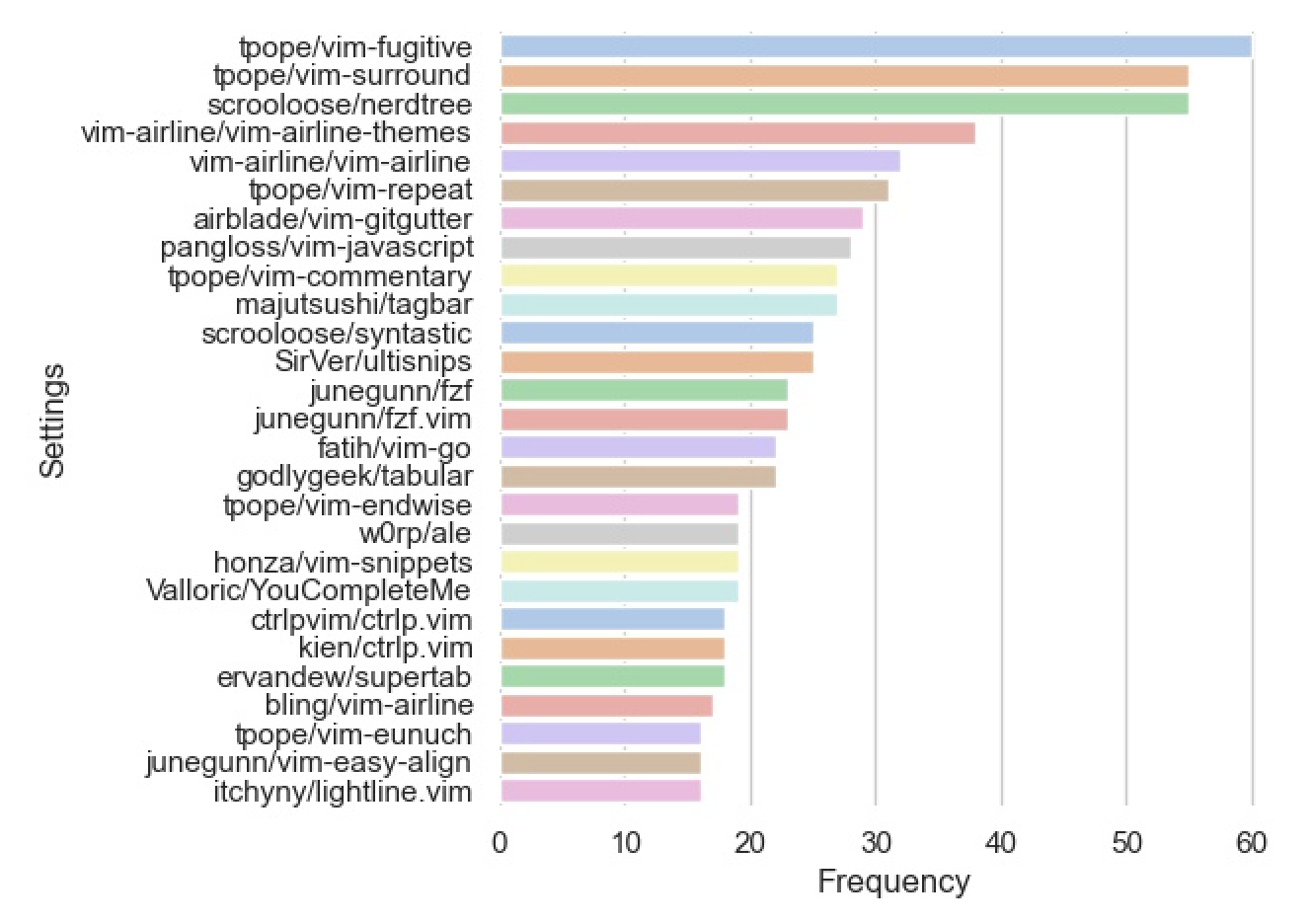
It makes sense that vim-fugitive, NERDTree, and vim-airline would be so popular since they add git support, a file tree, and an enhanced status bar respectively. It's also interesting to see how popular some of the tpope plugins are. In my experience, they do feel really natural and unobtrusive, like they could have been built into Vim. Other popular plugins add language-specific support, easier alignment, or improved fuzzy search capability.
When I set up my own .vimrc, I used vimawesome.com to sort through the most popular plugins. It's really validating to see that the analysis above roughly aligns with the listings on that site.
💡 Final Thoughts
There are a few ways this analysis could be improved in the future. Currently, it doesn't include any Neovim configurations. Also, if mappings or settings were separated out into a different file, they weren't included. Only the base .vimrc files were included. Lastly, there are a lot more synonyms for settings that I wasn't able to include in this analysis. So if some settings were specified using several different synonyms, they wouldn't be counted together in this analysis. Despite these drawbacks, the initial results were interesting enough and gave me a lot of good ideas for how to improve my own Vim configuration.
In the end, this ended up being a fun way to write some code with my new Vim setup. The analysis was simple, so most of the work centered around creating and cleaning the dataset. Still, from what I've read about data science, it sounds like this is often the case even in more complex analysis projects (and especially as the size and complexity of the datasets scale up). Yet this is easily overlooked in a lot of learning scenarios where a perfect dataset is already provided. In that way, I appreciated this project as a quick way to get my feet wet with data science and to learn a bit more about some of the popular ways to configure Vim.
Don't forget to check out the code on GitHub if you're interested.